Monitoring, Support, and IT Operations
AvierIT Tech provides managed IT services that keep infrastructure, cloud environments, business applications, and user support stable through proactive monitoring, maintenance, incident response, and operational reporting.
From cloud native platforms to legacy IT systems, our managed services provide reliability, faster response, and documented service ownership across day to day operations.
Our teams combine core IT services with automation so support, monitoring, and remediation keep improving over time.
Proactive. Predictive. Preventative.
Our managed services combine monitoring, incident response, patching, backups, and security under one SLA. Stay ahead of disruptions with proactive support and predictive alerts.
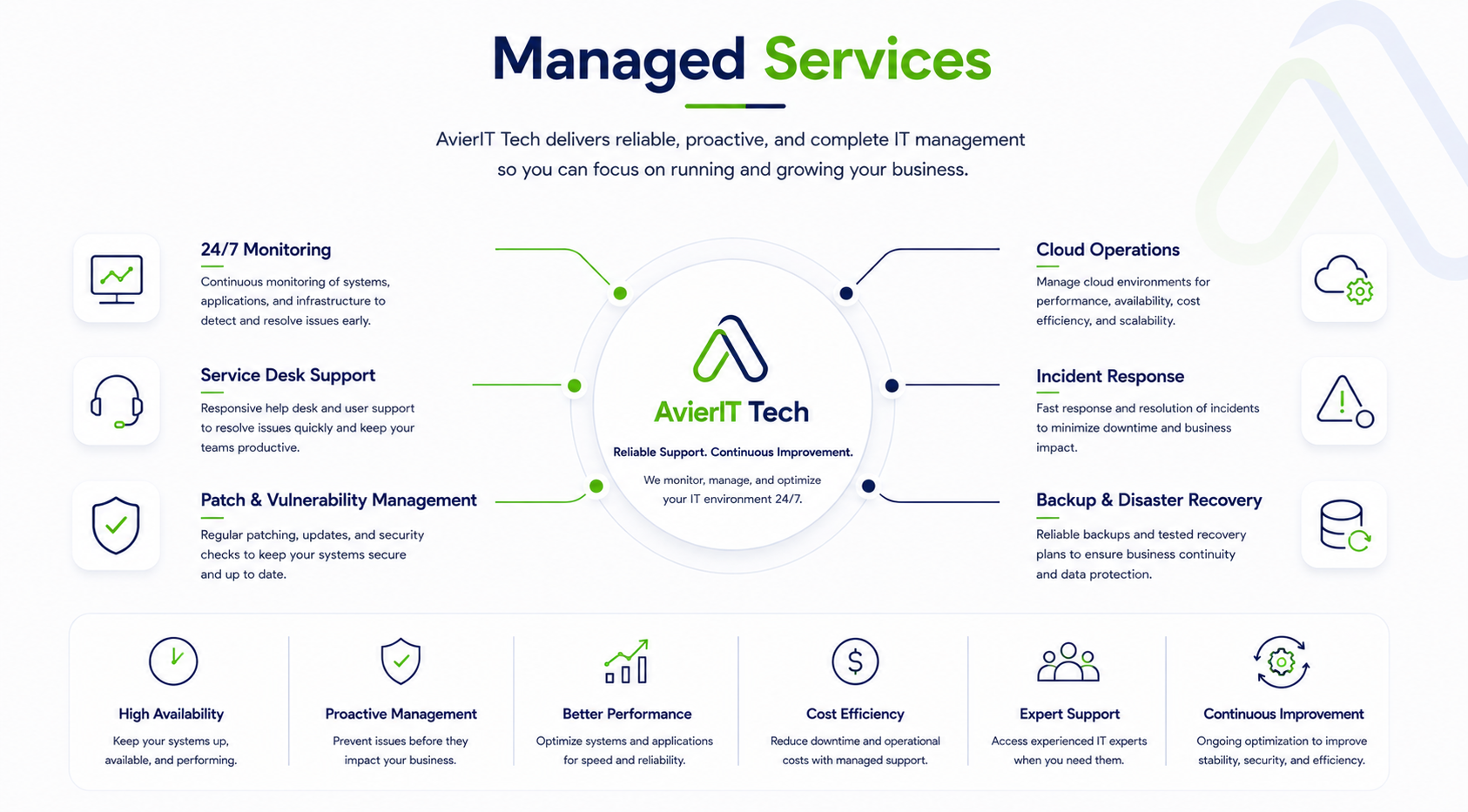
Talk to Our IT Ops TeamManaged Services Diagram
A structured visual summary of the page's core workflow, control points, and delivery focus.
Always On Scalable IT Support
Whether you're scaling to new regions, adopting hybrid cloud, or supporting remote teams, our managed services grow with you, securel and cost effectively.


Round the clock monitoring with real time alerts to ensure maximum uptime and performance.

Scalable infrastructure and cloud operations tailored to your workloads and compliance needs.

Multi tiered helpdesk support for employees, users, and stakeholders, backed by SLAs nd metrics.
What Is Included Managed Service Coverage That Extends Beyond Monitoring
We build managed service programs around uptime, service responsiveness, security, and the practical support your teams need to keep operations stable.
Monitoring, Incident Response, and Service Recovery
We detect issues early, triage quickly, and manage service interruptions with a structured operational response model.
- 24/7 monitoring, alerting, and escalation workflows
- Incident triage, resolution coordination, and root cause review
- Availability reporting and performance trend analysis
Cloud, Platform, and Environment Management
We support the day to day administration needed to keep infrastructure, applications, and releases healthy as your business changes.
- Patch management, release coordination, and environment upkeep
- Cloud cost visibility and capacity planning
- Backup validation, recovery planning, and access reviews
Service Desk, End Users, and Operational Governance
Managed services work best when technical operations and user support are aligned with clear ownership and measurable service levels.
- Helpdesk support and request fulfillment
- SLA reporting, service reviews, and governance checkpoints
- Knowledge management and process improvement recommendations
Service Operations View What Strong Ongoing Support Needs To Show
Managed services create confidence when clients can see service coverage, escalation quality, and the improvement activity happening behind day to day support tickets.
Support windows, escalation paths, and runbook maturity define how well a managed service responds when systems fail outside normal business hours.
Structured triage, root cause review, and trend reporting help teams solve recurring incidents instead of only clearing the alert queue.
Backup confidence, patch routines, service reviews, and access control hygiene reduce the operational risk that builds up quietly over time.
Managed Service Model The Workstreams Behind Dependable Support
Effective managed support combines service desk responsiveness, platform administration, incident control, and a formal improvement loop tied back to business stakeholders.
Service Desk Operations
Request triage, ticket ownership, user communication, and escalation routing determine whether support feels reactive or genuinely dependable.
Platform Administration
Environment upkeep, patching, release coordination, and access changes keep systems healthy as business needs evolve.
Incident Governance
Major incident handling, post incident review, and trend analysis give leadership visibility into where operational risk still remains.
Improvement Backlog
We convert recurring pain points into a managed backlog of fixes, automation opportunities, and service improvements instead of treating every issue as isolated.
Transition
We capture knowledge, review tooling, map service ownership, and define the support model.
Monitor
We run alerting, service desk workflows, operational dashboards, and coverage routines across the environment.
Resolve
We coordinate incidents, changes, requests, and communication with clear escalation handling.
Improve
We review service performance, recommend fixes, and prioritize changes that improve stability or speed.
Managed Services FAQs What Ongoing Support Usually Includes
We tailor operating coverage, governance, and escalation paths based on system criticality and the maturity of your internal team.
- Do you provide true 24/7 support or only business hours coverage?
-
Both are possible. Some clients need business hours operational coverage, while others require 24/7 monitoring and escalation for critical environments. We scope support windows based on uptime needs and service criticality.
- How do you take over support without disrupting current operations?
-
We onboard through a transition phase that includes knowledge capture, environment review, runbook creation, alert rationalization, access management, and agreed escalation procedures.
- Can managed services include applications as well as infrastructure?
-
Yes. We can support infrastructure, cloud environments, integrations, business applications, end user support, and delivery operations when those services need to be coordinated together.
- How do you report service performance back to clients?
-
We use regular service reviews, incident analysis, trend reporting, SLA metrics, and improvement recommendations so stakeholders can see what is happening and what needs attention next.